
Используйте Индекс, Люк! Архив блога: SQL, Производительность и тому подобное
Я не писал здесь некоторое время. Это не значит использовать индекс, Люк! заброшен или что-то подобное. Напротив, у меня есть некоторые темы в процессе разработки, о которых я надеюсь вскоре написать в блоге. Кроме того, используйте индекс, Люк! регулярно обновляется для отражения изменений в новых выпусках баз данных.
Последние обновления были сделаны несколько недель назад, когда был выпущен MySQL 8.0 (см. Мои записи в блоге “ Один гигантский скачок для SQL: выпущен MySQL 8.0 " а также " Большие новости в базах данных - лето 2018 «). Не стесняйтесь подписаться на мой современный SQL блог тоже ( RSS , Mailchimp ) так что вы не пропустите ни одной новости.
(Прочитайте больше)
Испанский перевод моей книги Объяснение производительности SQL только что был опубликован. Это пятый язык до сих пор ... теперь есть Немецкий , английский , Французский , японский язык а также испанский версия книги!

Вы можете купить его прямо у веб-сайт книги (PDF или мягкая обложка), а некоторые это также доступны через некоторые европейские магазины Amazon (только в мягкой обложке). Цены такие же, как и для других языков: 9,95 евро за PDF , 29,95 евро за печатную версию , 34,95 евро за PDF + мягкая обложка . Если вы заказываете из Закажите сайт, вы получите бесплатную доставку (по всему миру!)
Что касается других языков, весь испанский контент доступен бесплатно на https://use-the-index-luke.com/es/ ,
В рамках этой работы по переводу мы (переводчики и я) также обновили содержимое до последних выпусков базы данных: Db2 11.1, MySQL 5.7 ( тщательно сформулирован, чтобы он оставался верным для 8.0 ), Oracle 12c R2 и PostgreSQL 10.
Поскольку книга фокусируется на концепциях, потребовалось всего несколько изменений. Вот некоторые из наиболее важных:
Ничего страшного, правда? Если у вас есть печатная копия, не выбрасывайте ее;) Если у вас есть PDF-версия, вы можете скачать обновленную версию здесь (ссылка работает для всех языков).
(Прочитайте больше)
Переводы
Японский перевод этой статьи доступен Вот ,
Китайский перевод этой статьи доступен Вот ,
Несколько дней назад Uber опубликовал статью « Почему Uber Engineering перешла с Postgres на MySQL ». Я не читал статью сразу, потому что мой внутренний ботаник сказал мне вместо этого сделать некоторые домашние улучшения. При этом мой почтовый ящик заполнялся вопросами типа «Действительно ли PostgreSQL такой паршивый?». Зная, что PostgreSQL обычно не паршивый, эти сообщения заставили меня задуматься над тем, что, черт возьми, написано в этой статье. Этот пост является попыткой разобраться в статье Убера.
По моему мнению, в статье Uber в основном говорится, что они считают, что MySQL лучше подходит для их среды, такой как PostgreSQL. Тем не менее, статья делает паршивую работу по транспортировке этого сообщения. Вместо того, чтобы писать «PostgreSQL имеет некоторые ограничения для случаев использования с интенсивным обновлением», в статье просто говорится, например, «Неэффективная архитектура для записи». Если у вас нет прецедента с интенсивным обновлением , не беспокойтесь о проблемах, описанных в статье Uber.
В этом посте я объясню, почему я думаю, что статья Uber не должна восприниматься как общий совет по выбору баз данных, почему MySQL по-прежнему подходит для Uber и почему успех может вызвать больше проблем, чем просто масштабирование хранилища данных.
- ОБНОВЛЕНИЕ
- На ВЫБРАТЬ
- На перебалансировке индекса
- По физической репликации
- На разработчиков
- На успех
- По выбору Uber баз данных
(Прочитайте больше)
В последнее время SQL вышел из моды - отчасти из-за движения NoSQL, но в основном потому, что SQL часто все еще используется, как 20 лет назад. Фактически, стандарт SQL продолжал развиваться в течение последних десятилетий, что привело к текущему выпуску 2011 года. На этом занятии мы рассмотрим самые важные дополнения со времени широко известного SQL-92, объясним, как они работают и как PostgreSQL поддерживает и расширяет их. Мы подробно рассмотрим общие табличные выражения и оконные функции и кратко рассмотрим временные возможности SQL: 2011 и связанные с ними возможности PostgreSQL ».
Это тезис для моего выступления на FOSDEM в Брюсселе в субботу. Сообщество PostgreSQL было так любезно провести этот доклад в их ( слишком маленький ) devroom - отсюда и ссылки на PostgreSQL. Однако речь идет о стандартном SQL и охватывает функции, которые обычно доступны в DB2, Oracle, SQL Server и SQLite. MySQL пока не поддерживает ни одну из этих функций, кроме ОФСЕТ, который является злом ,
(Прочитайте больше)
В последнее время в блоге Use The Index, Luke, было тихо. Но это не потому, что у меня закончились темы для написания - фактически, мой блог, похоже, постоянно растет - недавнее молчание объясняется только тем, что в настоящий момент происходят более сложные проекты.
Прежде всего, воспользуйтесь индексом, у Люка появился новый талисман - не совсем свежие новости. Тем не менее, в настоящее время я готовлю раздачу и товары с новым талисманом. Оставайтесь в курсе.
(Прочитайте больше)

Знаете ли вы, что нумерация страниц со смещением очень хлопотна, но ее легко избежать?
Смещение указывает, что базы данных пропускают первые N результатов запроса. Однако база данных все равно должна извлечь эти строки с диска и привести их в порядок, прежде чем сможет отправлять следующие.
Это не проблема реализации, это способ смещения:
… Строки сначала сортируются в соответствии с <заказ по предложению>, а затем ограничиваются путем удаления количества строк, указанных в <предложении смещения результата> с начала…
SQL: 2016, часть 2, §4.15.3 Производные таблицы
Здесь важно то, что смещение принимает только один единственный параметр: количество строк, которые должны быть удалены. Нет больше контекста. Единственная вещь, которую база данных может сделать с этим числом, - это выборка и удаление такого количества строк. Другими словами, большие смещения налагают много работы на базу данных - независимо от того, является ли SQL или N о S Q L ,
Но проблема со смещением на этом не останавливается: подумайте, что произойдет, если новая строка вставится между двумя страницами?
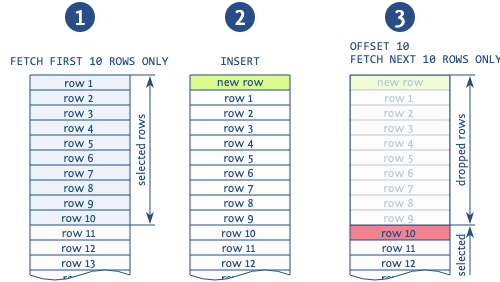
При использовании смещения ➌ для пропуска ранее извлеченных записей❶ вы получите дубликаты на случай, если между выборками двух страниц будут вставлены новые строки➋. Возможны и другие аномалии, это только самая распространенная.
Это даже не проблема с базой данных, это то, как фреймворки реализуют разбиение на страницы: они просто говорят, какой номер страницы выбрать или сколько строк пропустить. С одной только этой информацией никакая база данных не может сделать лучше.
Также обратите внимание, что проблема смещения возникает в разных синтаксисах:
Ключевое слово смещения
2-параметрический предел [смещение,] предел (предел 1 параметр в порядке)
Нижняя граница фильтрации основана на нумерации строк (например, row_number (), rownum,…).
Основная проблема всех этих методов в том, что они просто предоставляют количество строк, которые должны быть отброшены - больше нет контекста. В этой статье я использую смещение для ссылки на любой из этих методов.
- Жизнь без смещения
- Но рамки ...
- Распространить слово
(Прочитайте больше)
Итак, я был в PgCon 2014 в Оттаве дать краткую версию моего Обучение производительности SQL , Тем не менее, я думаю, что в конечном итоге узнать больше о SQLite чем о PostgreSQL там. Вот как это произошло и что я на самом деле узнал.

Ричард Хипп Создатель SQLite был основным докладчиком в этом году PgCon. В его лейтмотиве ( слайды , видео ) он сосредоточил внимание на трех темах: как PostgreSQL влиял на разработку SQLite (« SQLite изначально был написан из документации PostgreSQL 6.5 »И« Что будет делать PostgreSQL? »(WWPD), чтобы узнать, что нам пытается сообщить стандарт SQL). Второй основной темой было то, что SQLite следует рассматривать как формат файла приложения - альтернативу изобретению собственных форматов файлов или использованию ZIPped XML. Утверждение «SQLite не является заменой для PostgreSQL. SQLite - это замена гвоздям fopen () »(слайд 21). Наконец, Ричард уделяет большое внимание тому факту, что SQLite заботится о ваших данных (защита от сбоев, ACID) - в отличие от многих из так называемых систем NoSQL, которые Ричард называет «Постмодернистские базы данных: отсутствие объективной правды; Запросы возвращают мнения, а не факты ». В своем выступлении Ричард также показал, что SQLite довольно расслаблен, когда речь идет о типах данных. На самом деле, SQLite принимает строки типа «Hello» для полей INT. Обратите внимание, что он по-прежнему хранит «Hello» - данные не теряются. Я думаю, что он упомянул, что можно принудительно применять типы через ограничения CHECK.
(Прочитайте больше)
Это мой собственный и очень свободный перевод статьи, которую я написал для австрийской газеты. derStandard.at в октябре 2013 года. Так как эта статья была очень хорошо принята, и обсуждение SQL против NoSQL в настоящее время снова горячо, я думаю, что это подходящее время для перевода.
Назад в 2013 Регистр сообщил, что Google снова делает ставки на SQL. На первый взгляд это может показаться неожиданным, потому что это были публикации Google о Уменьшение карты а также Большой стол это дало толчок движению NoSQL в первую очередь. На второй взгляд оказывается, что существует тенденция использовать SQL или аналогичные языки для доступа к данным из систем NoSQL - и это даже не новая тенденция. Однако возникает вопрос: что останется от NoSQL, если мы снова добавим SQL? Чтобы ответить на этот вопрос, мне нужно начать с краткого описания истории баз данных.
- Top Dog SQL
- А потом: NoSQL
- Тем не менее: Вернуться к SQL
- Что осталось от NoSQL?
(Прочитайте больше)
Уважаемый MySQL,
Спасибо, что познакомили меня с SQL. Должно быть, это был 1998 год, когда мы впервые встретились с I и сразу влюбились в простоту SQL. До этого я использовал С структурами все время; Мне приходилось делать свои соединения программно, а также создавать и поддерживать свои индексы вручную. Было даже сложно объединить несколько условий поиска через и и или. Но затем появился новый блестящий мир SQL, который вы мне показывали ...
(Прочитайте больше)
В 2011 году я запустил 3-минутный тест: что вы знаете о производительности SQL. «Он состоит из пяти вопросов, которые следуют простому шаблону: каждый вопрос показывает пару запрос / индекс и спрашивает, демонстрирует ли он правильную индексацию или нет. До сегодняшнего дня этот тест стал одним из самых популярных Используйте Индекс, Люк и было завершено более 28 000 раз.
Заметка
На случай, если вам стало любопытно, учтите, что эта статья является спойлером. Вы можете захотеть сделайте тест самостоятельно прежде чем продолжить.
Хотя викторина была создана для образовательных целей, мне было интересно, смогу ли я получить некоторые интересные цифры из этих 28 000 результатов. И я думаю, что мог. Однако при взгляде на эти цифры нужно помнить несколько вещей. Во-первых, викторина использует фактор неожиданности, чтобы привлечь внимание. Это означает, что три вопроса показывают случаи, которые выглядят хорошо, но это не так. Один вопрос делает это наоборот и показывает пример, который может выглядеть опасно, но это не так. Есть только один вопрос, где правильный ответ соответствует первому впечатлению. Другим эффектом, который может повлиять на значимость результатов, является отсутствие репрезентативного отбора участников. Каждый может пройти тест. Вы даже можете сделать это несколько раз и, вероятно, получите лучший результат во второй раз. Просто имейте в виду, что викторина никогда не предназначалась для научных исследований при индексации знаний в данной области. Тем не менее, я думаю, что размер набора данных все еще достаточно хорош, чтобы произвести впечатление.
Ниже я покажу две разные статистики для каждого вопроса. Во-первых, средняя скорость, с которой этот вопрос был правильно ответил. Во-вторых, как эта цифра меняется для пользователей баз данных MySQL, Oracle, PostgreSQL и SQL Server. Другими словами, это говорит о том, что, например, пользователи MySQL лучше осведомлены об индексации как пользователи PostgreSQL. Спойлер: Это наоборот. Единственная причина, по которой мне повезло получить эти данные, заключается в том, что в тесте иногда используется специфический синтаксис поставщика. Например, то, что LIMIT в MySQL и PostgreSQL является ТОП в SQL Server. Поэтому участники должны сначала выбрать базу данных, чтобы вопросы отображались в собственном синтаксисе этого продукта.
- Вопрос 1: Функции в предложении WHERE
- Вопрос 2: Индексированные запросы Top-N
- Вопрос 3: Порядок столбцов индекса
- Вопрос 4: как поиск
- Вопрос 5a: индексное сканирование
- Вопрос 5b: Порядок столбцов индекса и операторы диапазона
- Общий балл: сколько прошло тест?
(Прочитайте больше)
Это один из самых стойких мифов, которые я видел в этой области. Это там на протяжении десятилетий. Если миф жив так долго, за ним должна быть какая-то правда. Итак, что может быть плохого в select *? Давайте посмотрим поближе.
Мы все знаем, что выбор «*» - это просто сокращение для выбора всех столбцов. Верьте или нет, это имеет большое значение для многих людей. Итак, давайте сначала перефразируем вопрос, используя эту «находку»:
(Прочитайте больше)

ОБНОВЛЕНИЕ : интеграция SQLFiddle была удалена в 2015 году из-за низкого уровня использования и больших усилий с моей стороны.
(Прочитайте больше)
Довольно часто меня спрашивают, что я думаю о подсказках к запросу. Ответ более длинный и, вероятно, также в два раза больше, чем ожидают большинство людей. Однако, чтобы ответить на этот вопрос раз и навсегда, я должен записать его.
Самый важный факт о подсказках запроса - то, что не все подсказки запроса родятся одинаково. Я различаю два основных типа:
Ограничение Советы
Большинство подсказок запросов являются ограничивающими подсказками: они ограничивают свободу оптимизаторов в выборе плана выполнения. «Подсказка» - это невероятно плохое название для этих вещей, поскольку они заставляют оптимизатор делать то, что ему было сказано - возможно, причина, по которой MySQL использует FORCE Ключевое слово для тех.
Мне не нравятся ограничивающие подсказки, но я иногда использую их для проверки различных планов выполнения. Обычно это происходит так: когда я считаю, что другой план выполнения может (должен?) Дать лучшую производительность, я просто намекаю на это, чтобы увидеть, действительно ли он дает лучшую производительность. Довольно часто это становится медленнее, и иногда я даже осознаю, что план выполнения, который я задумал, вообще не работает - по крайней мере, не с базой данных, с которой я работаю в данный момент.
Типичными примерами ограничения подсказок запроса являются подсказки, которые вынуждают базу данных использовать или не использовать определенный индекс (например, INDEX и NO_INDEX в базе данных Oracle, ИНДЕКС ИСПОЛЬЗОВАНИЯ и ИГНОРСКИЙ ИНДЕКС в MySQL или INDEX, FORCESEEK и тому подобное в SQL Server).
Так что с ними не так? Итак, две основные проблемы заключаются в том, что они (1) ограничивают оптимизатор и что им (2) часто нужны изменчивые имена объектов в качестве параметров (например, имена индексов). Пример: если вы используете подсказку для использования индекса ABC для запроса, подсказка становится неэффективной, когда кто-то меняет имя индекса на ABCD. Кроме того, если вы ограничите оптимизатор, вы больше не сможете ожидать, что он скорректирует план выполнения, если вы добавите другой индекс, который лучше обрабатывает запрос. Конечно, есть способы обойти эти проблемы. База данных Oracle, например, предлагает подсказки "index index" чтобы избежать обеих проблем: вместо указания имени индекса он принимает описание идеального индекса (список столбцов) и выбирает индекс, который лучше всего соответствует этому определению.
Тем не менее, я настоятельно рекомендую не использовать ограниченные подсказки запросов в производстве. Вместо этого вы должны выяснить, почему оптимизатор делает «неправильные вещи» и исправить причину. Ограничительные подсказки устраняют причину, а не причину. При этом я знаю, что иногда нет другого разумного выбора.
Вспомогательные подсказки
Вторым основным типом подсказок запроса являются вспомогательные подсказки: они поддерживают оптимизатор, предоставляя информацию, которой у него нет в противном случае. Вспомогательные подсказки редки - я знаю только несколько хороших примеров, и самый полезный уже устарел: это FAST number_rows (SQL Server) и FIRST_ROWS (п) (Oracle). Они сообщают оптимизатору, что приложение планирует извлечь только столько строк результата. Следовательно, оптимизатор может предпочесть использование индексов и объединений вложенных циклов, которые были бы неэффективны при получении полного результата (см. Глава 7, Частичные результаты Больше подробностей). Хотя это несколько устарело, я все еще использую эти подсказки в качестве определяющего примера для поддержки подсказок, потому что они предоставляют информацию, которую оптимизатор не может иметь иначе. Этот конкретный пример настолько важен, что стоило определить новые ключевые слова в ISO SQL: 2008: FETCH FIRST ... ROWS ONLY и OFFSET. Вот почему эта подсказка является очень хорошим, но устаревшим примером поддержки подсказок по запросу.
Другим примером поддержки подсказок является (недокументированная) подсказка CARDINALITY базы данных Oracle. Это в основном перезаписывает оценку количества строк подзапросов. Этот совет часто использовался, если комбинированная селективность двух предикатов была далеко от результата селективности каждого отдельного предиката (см. « Пример комбинированной селективности » ). Но эта подсказка также устарела, поскольку введена база данных Oracle 11g. расширенная статистика чтобы справиться с такими вопросами. SQL Server отфильтрованная статистика служить той же цели. Если ваша база данных не может отразить корреляцию данных в ее статистике, вам придется прибегнуть к ограниченным подсказкам.
Подсказка Oracle OPT_ESTIMATE каким-то образом является наследницей подсказки CARDINALITY для случаев, когда оценки все еще выключены. Пифян написал хорошая статья о OPT_ESTIMATE ,
Похоже, что вспомогательные советы не так уж и плохи: это всего лишь способ справиться с известными ограничениями оптимизатора. Вероятно, поэтому они имеют тенденцию устаревать, когда оптимизаторы развиваются.
(Прочитайте больше)
Вот еще одна слайд-колода для моего выступления «Нумерация страниц выполнена правильно», которое я давал во многих случаях.
Пожалуйста, взгляните также на эту запись в блоге Гари Миллсапа о « Пандус ». Вы видите, как использование OFFSET реализует этот анти-шаблон?
(Прочитайте больше)
Я думаю, что на самом деле я никогда не разделял слайды своего выступления в Париже на Dalibo-х Сессия PostgreSQL о производительности. Итак, вот они.

Когда клиенты рассказывают мне о своих планах инвестировать в хранилище SSD для своей базы данных, они часто смотрят на меня как на доктора, рассказывающего пациенту о его смертельной болезни. Я не обсуждал это со своими клиентами до недавнего времени, когда один клиент сразу спросил меня: «Как специалист по настройке SQL, ты боишься SSD, потому что это убивает твою работу?» Вот что я сказал этому клиенту.
(Прочитайте больше)
Несколько недель назад я пригласил вас принять участие в опросе о вашем интересе к обучению SQL-производительности для разработчиков. В то же время есть график Немецкий а также английский тренинги доступны. В частности, я бы хотел отметить четыре онлайн-курса Я даю в летнее время. Надеюсь увидеть тебя там.
Еще одна возможность для короткой встречи - конференции, на которых я буду присутствовать и / или выступать. Следующим является День разработчиков PostgreSQL в Праге (p2d2) следующий четверг. Вы можете купить Объяснение производительности SQL там (700 крон; в перерывах и после конференции). Следующая конференция, которую я уже могу подтвердить, состоится в этом году. PostgreSQL Конференция Европа в Дублине конец октября. Возможно, вы заметили, что я недавно посещал множество конференций PostgreSQL (Брюссель в феврале, Париж в марте). Я тоже планирую посещать другие конференции, и я только что подал несколько предложений для выступлений на других конференциях. Я дам вам знать, если они будут приняты.
(Прочитайте больше)

« ОРМ не совсем бесполезны ... «Я просто написал в твиттере в ответ на не совсем конструктивное сообщение о том, что мы должны уволить разработчиков, которые хотят использовать ORM. Но потом я продолжил не совсем конструктивным тоном, когда писал « … проблема в том, что авторы ORM ничего не знают о производительности базы данных ».
(Прочитайте больше)
Привет!
Не могли бы вы уделить мне несколько минут и немного помочь?
(Прочитайте больше)
Хорошие новости всем. У меня сегодня хорошее настроение;) Я объясню. Прежде всего, французское издание Объяснение производительности SQL почти готово и отправит в конце месяца ( Предварительный заказ сейчас ;). У него другое имя ( SQL: Au cœur des performance ) но в остальном то же самое. Итак, это вызвало какое-то чувство «выполненного проекта».
Далее я дал несколько хороших тренинги в последнее время и с нетерпением ждем еще в ближайшие недели. Это просто потрясающе, когда аудитория задает замечательные вопросы, но еще более удивительно, если они приходят с хорошими выводами, которые подтверждают их правильное понимание. Это вызывает чувство "пропущенного выполненного".
(Прочитайте больше)

В прошлые выходные я посетил Европейское собрание разработчиков свободного и открытого программного обеспечения (FOSDEM) в Брюсселе, Бельгия. Это огромная и бесплатная конференция, посвященная бесчисленным темам с открытым исходным кодом, таким как Open / Libre Office, Microkernels, MySQL, NoSQL, PostgreSQL, OWASP и многим другим.
(Прочитайте больше)

Хорошие новости для всех - ну, по крайней мере, если вы говорите по-французски. Использовать Индекс, Luke и объяснение производительности SQL будут переведены. Вы уже можете начать читать первые главы Вот ,
(Прочитайте больше)
Вы можете догадаться об этом, но я не зарабатываю на этом сайте, а продажи книг не оплачивают все счета, хотя книги оплачивают некоторые счета, спасибо! Однако, чтобы оплатить оставшиеся счета, я занимаюсь коучингом, тренингами и консультациями. Вы можете найти все подробности на моем профессиональном сайте http://winand.at/ но я хотел бы выделить один сервис здесь: Мгновенный коучинг ,
Попробовав поиск в Google и попробовав множество способов решить проблему, возникло ли у вас чувство смирения, когда вы просто хотите спросить кого-то, кто должен знать ответ? Ну, это Instant Coaching - по крайней мере, если ваша проблема связана с производительностью и / или базами данных.
(Прочитайте больше)
С небольшой задержкой всего в три недели я пишу кое-что об этой конференции PostgreSQL в Европе.
Включая учебный день, он был заполнен четырьмя днями работы с базами данных - другими словами: отличное время, если вы любите базы данных :) Но давайте начнем с самого начала.
(Прочитайте больше)
Если вы не следуете моим советам по производительности SQL ( @SQLPerfTips ) кормите в твиттере, вам очень не хватает. Тем не менее, две вещи, которые вы, вероятно, должны знать, даже не используя твиттер:
All You Base Conf - База данных конференции для веб-разработчиков
Я никоим образом не связан с этими ребятами, но они были так рады предложить скидочный код для моих читателей (подписчиков?). Конференция состоится в Оксфорде, Великобритания, 23 ноября 2012 года. http://allyourbaseconf.com/ Больше подробностей. Используйте промо-код «SQLPerf», чтобы получить £ 35 от стандартной цены билета.
Празднование 10 000 подписчиков
мой @SQLPerfTips счет недавно пересек отметку 10 тыс. подписчиков. Поэтому я, однако, отмечу это с помощью другого кода скидки (10kflwrs), который подходит для -10% для заказов «Объяснение производительности SQL» при размещении непосредственно на http://sql-performance-explained.com/ , Срок действия этого кода истекает в пятницу, 12 октября, в 20:00 по местному времени (CEST). Это 11 утра PDT, например.
Как упоминалось ранее, я буду в в этом году конференция PostgreSQL в Праге , Осталось еще две недели, но у меня было всего несколько минут «свободного» времени и я подготовил свой личный график.
Как обычно, я планирую посетить как можно больше сессий. Как обычно, я пропущу некоторые в пользу хорошего чата и / или передумаю в последний момент.
(Прочитайте больше)
«Используйте Индекс, Люк!» Сегодня исполняется вторая годовщина. К сожалению, я не смог ничего подготовить к этой годовщине, как в прошлом году, когда я представил 3-х минутный тест Тест по-прежнему очень популярен, кстати, его берут около 20 раз в день. Тем не менее, все, что у меня есть на этот юбилей, это обещание.
Вы знаете http://sqlfiddle.com/ ? Вы должны;) Это онлайн-инструмент для тестирования SQL-запросов с пятью различными базами данных (SQL Server, MySQL, Oracle, PostgreSQL и SQLite). Это не облачная база данных, которую вы могли бы использовать для создания приложений. SQLFiddle - это инструмент для совместной онлайн-работы над проблемами SQL. Он был создан для улучшения вопросов и ответов на вопросы, связанные с SQL, на таких сайтах, как Stackoverflow.
(Прочитайте больше)
После публикации англоязычного издания «Объяснение производительности SQL» возникла огромная потребность в электронном издании. После нескольких дней ответов на эти вопросы, я, вероятно, проще предложить электронную книгу, чем объяснять, почему ее нет. Ну, я должен признать, что я не очень много читаю электронные книги. У моей жены есть устройство e-ink, но оно почти не используется (вероятно, из-за отсутствия немецкого контента). Я загрузил предварительный релиз ePUB с 2011 года (больше не доступен) и должен сказать, что он работает, но это не очень приятно. Тем не менее, многие люди сказали мне, что они будут в порядке с PDF, потому что они в любом случае используют планшеты или смартфоны для чтения своих электронных книг. Перемотка вперед на несколько недель: с понедельника я могу предложить загрузку в формате PDF всего за 9,95 евро (английский, немецкий [обновление] или французский, вы выбираете).
После этого возник огромный спрос - опять же - на скидки при покупке как PDF, так и бумажной копии. Это застало меня врасплох. Не то, чтобы люди хотели скидку, но что люди хотели бы купить оба издания. Поэтому я спросил, выслушал и узнал кое-что о моем собственном бизнесе.
(Прочитайте больше)
Наконец-то мне удалось выложить все ошибки, о которых читатели до сих пор сообщали в Интернете. Я не совсем этим горжусь, но уже есть более 30 известных опечаток для немецкого издания. На складе еще есть несколько немецких копий «Объяснение производительности SQL», но мне кажется, что скоро мне нужно будет организовать вторую печать. Я приму все эти ошибки для второй печати. Английское издание имеет только две опечатки на данный момент, но я сомневаюсь, что он останется таким низким. Мы будем рады сообщить о любых найденных вами ошибках. Я следую за ними :)
А теперь что-то другое: обычаи. Я получил несколько запросов, могу ли я указать, сколько таможенных пошлин вам придется заплатить, если вы закажете книгу за пределами ЕС. Ну, я не могу сказать вам точную сумму, но помогу вам в Google;) Важная информация, которая вам нужна, чтобы найти курс в вашей стране, это так называемая HS номер и происхождение товара. Я должен поместить эту информацию в таможенную декларацию CN22 снаружи упаковки, чтобы власти знали, что внутри. Номер HS для книг 490199, и эта конкретная книга напечатана в Австрии. Вот что я пишу в форме таможенной декларации. Мне также сказали, что некоторые страны могут взимать другие сборы помимо таможенных (например, НДС). Извините, не знаю больше деталей.
(Прочитайте больше)
В последние несколько недель, здесь, в « Использовать индекс», Люк стал немного молчать ! Сегодня я хотел бы рассказать вам новости, которые вызвали молчание, и дать краткий обзор о будущем использования индекса, Люк!

Самая важная новость в том, что я стал отцом. Это очень важно для меня, по крайней мере. Мой сын, Марсель, родился 25 марта 2012 года. Итак, у нас уже было два месяца, чтобы успокоиться. Мама неплохо справляется в ночную смену - я могу спать почти нормально, и у меня достаточно времени и энергии для работы в дневное время.
(Прочитайте больше)
Используйте Индекс, Люк! был один сегодня.
В этом году был достигнут некоторый прогресс. Помимо постоянно растущего содержания, я особенно рад, что приложения о планы выполнения и пример схемы охватывает MySQL, PostgreSQL и SQL Server в дополнение к Oracle.
(Прочитайте больше)
Обновление 2017-05-23
MariaDB 10.2 представила поддержку общих табличных выражений.
Обновление 2018-04-19
В MySQL 8.0 появилась поддержка общих табличных выражений.
Генератор строк - это метод для создания нумерованных строк по требованию. Можно построить генератор строк на чистом стандартном SQL, используя рекурсивный общие табличные выражения (CTE) Позвонил с оговоркой. Если вы никогда не слышали о предложении with, возможно, это связано с тем, что MySQL не реализует эту специфическую часть стандарта SQL-99 ( запрос функции от 2006 года ). В этой статье представлены представления генератора для MySQL. Не такой мощный, как рекурсивные CTE, но в большинстве случаев достаточно хороший. Но прежде чем углубляться в детали реализации, я покажу вам пример использования генератора строк.
(Прочитайте больше)
У меня есть одно желание для каждой базы данных. Некоторые из них - большие пожелания, поэтому я подумал, что лучше отправлю их пораньше. Знаешь, всего шесть месяцев до Рождества;)
оракул
'' НУЛЕВОЙ? Ты серьезно? Я знаю это всегда был таким , но значит ли это, что так будет всегда?
SQL Server
Не могли бы вы включить READ_COMMITTED_SNAPSHOT по умолчанию? Или, по крайней мере, сделать это обязательным вопросом при создании базы данных? Это может предотвратить так много проблемы с блокировкой ,
PostgreSQL
Не могли бы вы осуществить сканирование только по индексу (ака "индексы покрытия")? Это отличная производительность, которая мне очень не нравится в PostgreSQL.
ОБНОВЛЕНИЕ : Это стало правдой с PostgreSQL 9.2 ,
MySQL
Не могли бы вы реализовать хеш-соединение алгоритм? Многие приложения страдают от плохой производительности соединений только потому, что в MySQL нет хеш-соединений.
С сегодняшней точки зрения, похоже, что мое желание PostgreSQL - единственное, что может сбыться. Но я буду продолжать надеяться и на других.
При этом мой почтовый ящик заполнялся вопросами типа «Действительно ли PostgreSQL такой паршивый?»И« Что будет делать PostgreSQL?
Однако возникает вопрос: что останется от NoSQL, если мы снова добавим SQL?
Итак, что может быть плохого в select *?
Должен?
Так что с ними не так?
Вы видите, как использование OFFSET реализует этот анти-шаблон?
Я не обсуждал это со своими клиентами до недавнего времени, когда один клиент сразу спросил меня: «Как специалист по настройке SQL, ты боишься SSD, потому что это убивает твою работу?
Не могли бы вы уделить мне несколько минут и немного помочь?
Подписчиков?